Or,
No Performance for you, go home now.
Today's blog post is a guest appearance by our Benevolent Dictator and Glorious Leader, Marty Roesch.
We asked Marty for his thoughts on threading, performance and processing network data. Here's what we got:
Executive Summary
Performance of processes on current- and next-generation Intel CPUs is closely tied to proper cache utilization. Claims being made regarding Snort’s capability to maximize performance of today’s multi-core platforms are ignorant of the Intel CPU architecture and the steps that can be taken to make it perform on that architecture. Performance of Snort-like packet processing has nothing to do with threading and everything to do with proper load allocation on the available computing resources of a device. Sourcefire has demonstrated that Snort can perform at very high speeds on both single and multi-core machines by virtue of proper configuration and load allocation.
Discussion
There is a lot of FUD being thrown about in the IDS/IPS world regarding single threaded versus multi-threaded packet processing in the Snort detection engine architecture and its impact on top-line performance. The claims being made generally center on the age of Snort’s engine architecture and the appropriate utilization of compute resources on the modern Intel architecture. This paper will analyze the primary claims and provide a technical briefing on the matter at hand.
Intel CPU Architecture
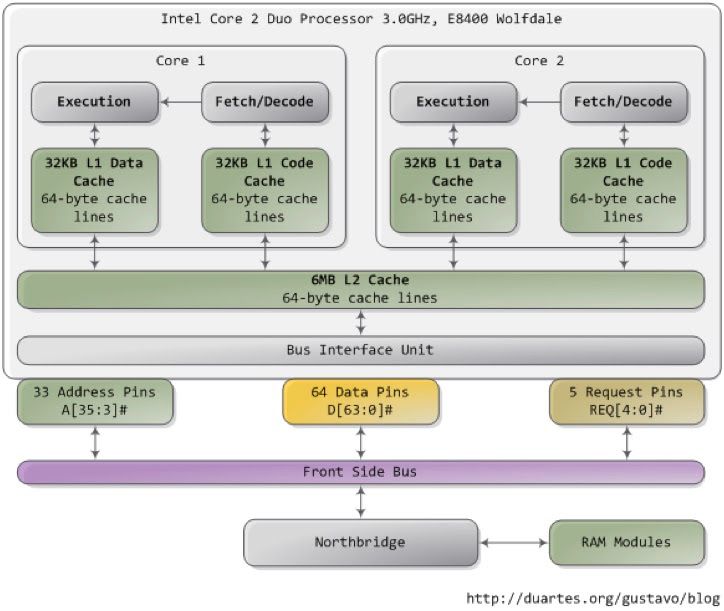
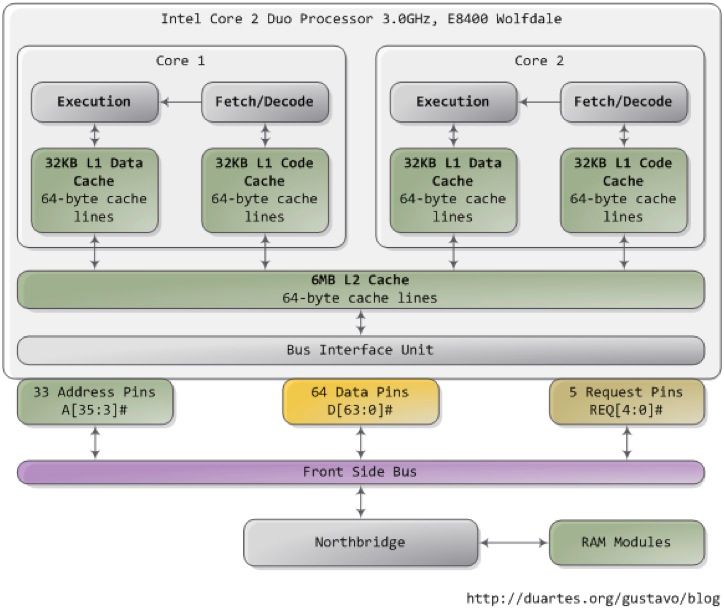
One of the first things to understand about the Intel CPU is that it relies heavily upon cache for its performance. When a program is run its code and data are loaded into system memory and they are processed by the CPU. Read/Write Access to system memory is much slower than the CPU can process data through its primary processing logic so Intel added caching to its CPUs to prevent them from spending most of their time waiting for memory accesses. On the Intel Core 2 Duo architecture shown above there are two caches, an L1 cache which is very fast and small (due to the expense of making memory that fast) and a much larger L2 cache which is somewhat slower than L1 but much faster than system memory.
When a program is running, the CPU tries to predict which memory it’s going to need next and loads the L1 and L2 caches appropriately to minimize time spent waiting on memory access. Programs that perform very poorly will frequently be seen to be inefficient at the cache level exhibiting a large number of “cache misses”. In these programs the CPU burns so many cycles waiting for the cache to be refilled with needed data that performance suffers. Fast programs are built to take maximum advantage of the cache architecture of the CPU.
With today’s multicore CPUs this picture gets more complicated. In a multicore CPU with multiple processes spread across different cores the same rules apply in general. A program with efficient cache attributes will perform better than one that is cache inefficient. The complication comes when the programs become multi-threaded in the multi-core environment.
The idea behind multithreading is to speed up throughput of a process by having multiple simultaneous threads of execution working on multiple pieces of data. A multithreaded process that has one thread stalled waiting for data can execute another thread on another piece of data which maintains high overall throughput in the system. For processes that take maximum advantage of this arrangement there can be substantial performance improvements.
There is downside, however. Threads that are spread across CPU cores which operate on the same data have to keep their caches synchronized (or, coherent). As shown in the diagram above, there is an L1 cache per core and a shared L2 cache on the Intel Core 2 CPU architecture. This architecture is the same on all current Intel x86 CPUs. When there are two different threads operating on the same data executing across two different cores in this architecture, the L1 caches have to be synchronized with one another essentially for every access across the L2 cache. Boiling it down, every time you access memory (even for a read) you have to spend some clock cycles synchronizing the cache.
The downside gets even worse if the threads are spread across multiple CPU dies (the physical chips themselves). Multi-die systems are very common today, for example recent Intel 4-core CPUs are really two 2-core dies in a common package. When the threads are running on multiple physical dies and there’s a cache coherency update to keep the local L1/L2 caches synchronized the updates happen across the main memory bus (or, front side bus). The front side bus is much slower than the CPU cache and it’s also a broadcast bus, all devices that are plugged into it have to look at any message on the bus to figure out if its for them or not. Things that are plugged into the bus include all the CPUs on the system and the main memory.
Looking at the architecture of the Intel CPU a few things become very clear when looking at writing high performance code. Threads should access data on their own core only. Accessing a single piece of data across multiple cores has major performance impact that will not be made up for by increased throughput in a serial packet processing framework like Snort.
Snort Architecture and Design
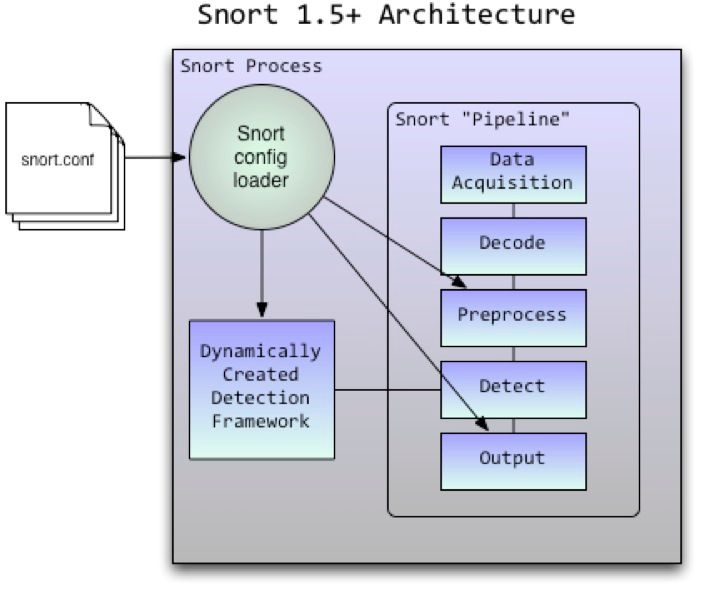
Snort is a single-threaded multi-stage packet processing pipeline, it runs on one CPU core and the data that it processes stays resident on that core and in that cache. Packets arrive off of the network serially and are processed in the order of reception. If the bandwidth being passed by the network interface associated with a Snort instance is greater than it can handle more instances of Snort can be launched and the traffic can be load balanced across the instances. That is how Sourcefire sensors achieve their high multi-gigabit performance today, a kernel-based load balancing mechanism drives traffic to multiple Snort instances that each run on a single CPU core and can consume over a gigabit per second per core of traffic.
This design has some inherent advantages. It is simple and rugged, there are no corner cases that can cause deadlock and freeze the processing pipeline for multiple cores of execution. Because it doesn’t use threading it doesn’t suffer from concurrency and locking overhead required to maintain the internal consistency of a multithreaded application which hinder performance. Putting the load balancing mechanism outside of Snort allows multiple (hardware or software based) methods to be utilized to increase aggregate system performance.
In short, today’s Snort architecture is well suited to take advantage of modern Intel CPU design when intelligently paired with load balancing and platform resource management.
The case for Intelligent Multithreading
Multithreading can be useful for several things in an application like Snort:
- Presenting a single point of more interactive management for multiple analysis threads with the same configuration.
- Sharing information between threads to provide additional detection information.
- Load-balancing across threads with a common configuration.
In the first case, it can be seen that in a given Snort instance a “nice to have” would be a unified interactive management interface to a set of Snort instances for the purposes of managing the configuration and runtime behavior of the overall process. SnortSP implements this idea by providing a shell interface that allows a user to construct a traffic analysis thread from major components (data source, analytics, etc) and run them against an interface set while maintaining interactive access to the analyzer thread. Any modern IPS implementation that provides the level of functionality that Snort does (i.e. open source, extensible platform) should have a similar capability built into it.
The second case of information sharing is useful for a number of applications. In a multithreaded instantiation where different threads are performing different tasks (e.g. Snort/RNA) on copies of the same data there can be very useful data exchange between the threads such as real-time detection tuning or multi-session attack correlation. The key here is that if two threads are operating on the same data that the data for each thread reside in independent memory space so that the CPU cache management system doesn’t attempt to keep the caches synchronized. There will be some overhead for the initial buffer creation and copying but this will be far less than the cache sync overhead.
The third case is one of load balancing traffic across multiple instances of Snort with a common configuration. Functionally this is the same as what is being done today on Sourcefire sensors except that the load balancing happens in the process and is made less efficient than the current mechanisms due to synchronization and locking overhead of the thread management system. Given the performance that is seen in the Snort 2.x code base today this third option is not particularly desirable on the x86 platform.
The Intel architecture lends itself to an optimal application architecture where one thread that runs on a single CPU core processes an individual piece of data and then moves on to the next one. Multiple threads are useful on that CPU core if a single thread would stall the CPU while waiting for data to load or an instruction to execute. Several of the research paths currently being pursued by Sourcefire involve this architecture.
If the top level worst case of Snort performance is an optimization target then a new detection engine architecture should be investigated. The current model that buffers and processes packets has memory management and processing overhead that has worst-case performance implications that are noticeable to the user of the system. A new processing architecture that utilized in-sequence packet processing via finite state machines (FSM) and reduced or eliminated buffering could see significant performance gains over the current detection architecture.
What Not To Do
An architecture that should be avoided at all costs is a threading system that spreads the computational load of a single piece of data across multiple CPU cores. This approach will maximize cache misses on any single core and require continuous reloading of the cache across the multiple CPU cores that are involved in data processing as well as constant cache synchronization. An architecture that implements this mechanism will have very bad worst case performance and its best case performance will be far below what can be achieved per core on a single threaded application performing the same tasks.
Conclusion
In this paper the architecture of the Intel CPU and Snort were explored as well as the architecture of multithreaded applications and their interaction with the Intel caching model. An analysis of different cases for multithreading Snort-like applications was also performed. In the real world performance claims of one architecture versus another it can be shown that the Snort 2.x architecture is highly optimized for today’s CPUs when paired with an intelligent load balancing mechanism.